txt
Ответы в темах
-
АвторСообщения
-
как известно, при использовании set(list) мы преобразуем исходный список во множество , то есть элементы становятся неупорядоченными (в сравнении с исходным списком) и уникальными.
Один из способов сохранить порядок исходного списка с уникальными элементами:
(для сравнения используем также set):
inn = [9,8,8,7,5,5,7]
set=set(inn)
set_save_order=[ els for indx,els in enumerate(inn) if inn.index(els)==indx ]
OUT = set, set_save_order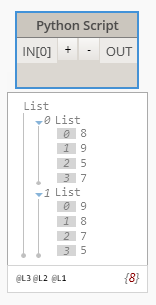



textNoteTypesName = [ doc.GetElement(i).get_Parameter(BuiltInParameter.SYMBOL_NAME_PARAM).AsString() for i in doc.GetElement(ElementId(3195150)).GetValidTypes()]
У меня получилось так:

Транспонирование вложенных списков :
lst=[["a",1],["b",2],["c",3]]
lst_transpose=[[lst[j][i] for j in range(len(lst))] for i in range(len(lst[0]))]
OUT=lst_transpose >>> [["a","b","c"],[1,2,3]]
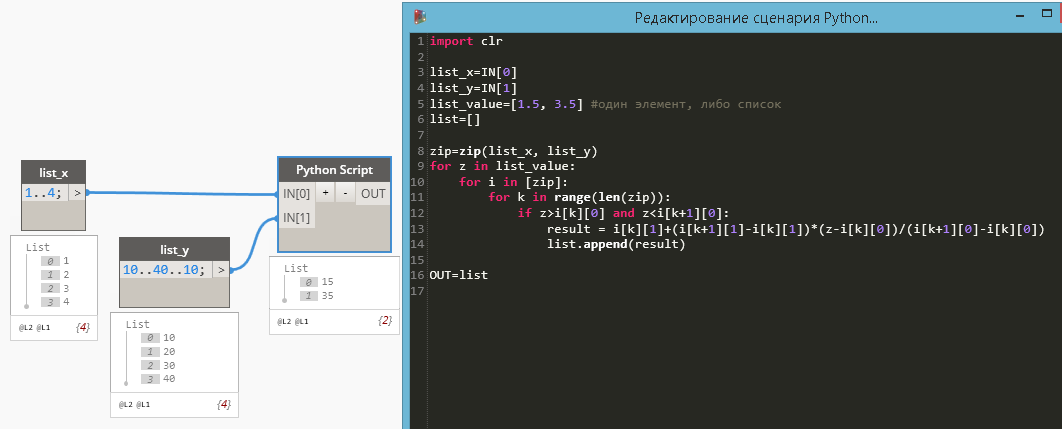
Из пакета Springs есть такой watch (результат можно выделить и скопировать в буфер, окошко растягивается) :

import clr
clr.AddReference('ProtoGeometry')
from Autodesk.DesignScript.Geometry import *
lst=[[-4,-8,-7.5],[-50,-200,-7.5]]
list=[[Point.ByCoordinates(0,0,x*304.8) for x in i ]for i in lst]
OUT = listp.s.
обратная задача выполняется уже в транзакции:import clr
clr.AddReference("RevitServices")
import RevitServices
from RevitServices.Persistence import DocumentManager
from RevitServices.Transactions import TransactionManager
doc = DocumentManager.Instance.CurrentDBDocument
clr.AddReference("RevitAPI")
import Autodesk
from Autodesk.Revit.DB import *
TransactionManager.Instance.EnsureInTransaction(doc)
OUT=[[WallUtils.AllowWallJoinAtEnd(i, 1), WallUtils.AllowWallJoinAtEnd(i, 0)] for i in UnwrapElement(IN[0]) ]
TransactionManager.Instance.TransactionTaskDone()
напишу здесь чтобы сохранить
иногда бывает нужно чтобы цикл пробегал в такой последовательности: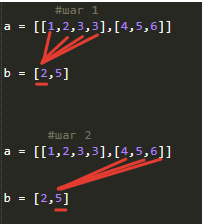
вот скрипт :
результат: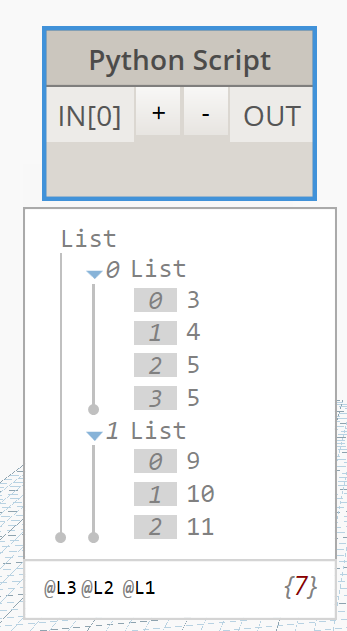
Спасибо!
все работает:import clr
clr.AddReference('RevitAPI')
from Autodesk.Revit.DB import *
clr.AddReference('RevitNodes')
import Revit
clr.AddReference('RevitServices')
import RevitServices
from RevitServices.Persistence import DocumentManager
from RevitServices.Transactions import TransactionManager
doc = DocumentManager.Instance.CurrentDBDocument
TransactionManager.Instance.EnsureInTransaction(doc)
delete_els=[doc.Delete(UnwrapElement(i).Id) for i in IN[0]]
TransactionManager.Instance.TransactionTaskDone()
также подсмотрел такой метод CHOP:
http://dynamobim.ru/forums/search/замена+текста/
для вашего случая (этот пример тоже на форуме есть):
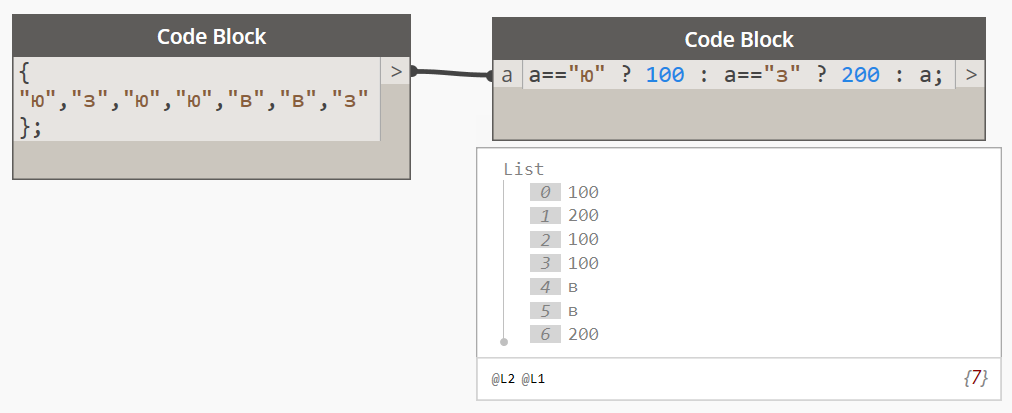
тут подробно:
false/true – нужен просто для перезапуска скрипта
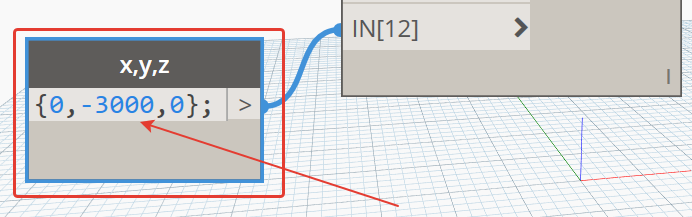
по поводу “3 метра над уровнем базовой точки проекта” – можно передвинуть оси по x,y,z
вот самую малость внес изменений: https://yadi.sk/d/q7_Q0LeN3TiVfr


+ несколько else if
inn=[1,2,3,0,1]
lst=["a" if i==3 else "b" if i==2 else "c" if i==1 else "not exist" for i in inn]
OUT = lst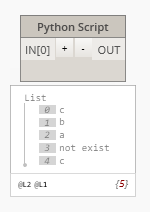
Подскажите , а зачем вам писать False ?
Может я ошибаюсь, но полагаю, что в конечном счете вам нужен список, содержащий определенные текстовые вхождения ? Если это так , то , при условии уникальности двух списков, как вариант :
(на выходе получаем: 1 список- список содержит … 2 список- не содержит…)
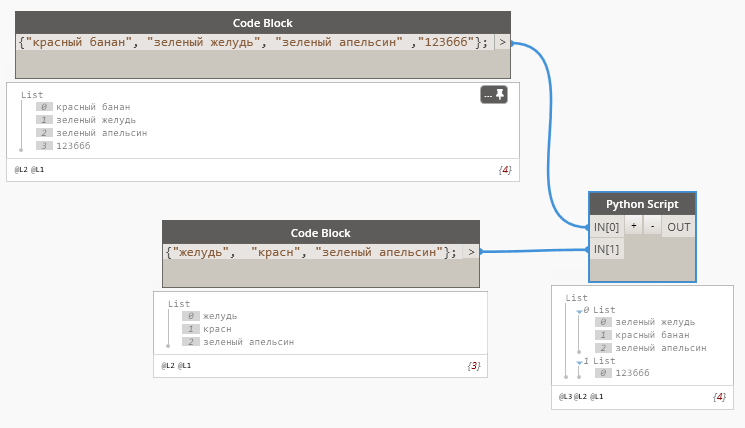
Код в питоне:
list_contain=[i for x in IN[1] for i in IN[0] if x in i]
list_not_contain=set(IN[0])-set(list_contain)
OUT=list_contain, list_not_containp.s. бывает, что нужно получить не сами элементы с вхождениями , а их индексы:
index_contain=[IN[0].index(i) for x in IN[1] for i in IN[0] if x in i] -
АвторСообщения